OpenGL入门
配置
…
初始化GLFW
类似于实例化窗口
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
glfwWindowHint(GLFW_OPENGL_FORWARD_COMPAT, GL_TRUE); //MAC OSX needs设置窗口分辨率、标题等
GLFWwindow* window = glfwCreateWindow(800, 600, "LearnOpenGL", NULL, NULL);
if (window == NULL)
{
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
glfwMakeContextCurrent(window);窗口持续展示
while(!glfwWindowShouldClose(window))
{
processInput(window);
key_callback(window, GLFW_KEY_ESCAPE, 0, GLFW_PRESS, 0);
glClearColor(0.9f, 0.3f, 0.3f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT);
glfwSwapBuffers(window);
glfwPollEvents();
}
glfwTerminate();其中大部分函数可以根据命名得出含义
glfwPollEvents()类似于监听是否有键盘、鼠标等输入
输入
void key_callback(GLFWwindow* window, int key, int scancode, int action, int mode)
{
// 当用户按下ESC键,我们设置window窗口的WindowShouldClose属性为true
// 关闭应用程序
if(key == GLFW_KEY_ESCAPE && action == GLFW_PRESS)
glfwSetWindowShouldClose(window, GL_TRUE);
}
// 在while循环中写
key_callback(window, GLFW_KEY_ESCAPE, 0, GLFW_PRESS, 0);
// 使用回调函数
glfwSetKeyCallback(window, key_callback);换种写法
void processInput(GLFWwindow *window)
{
if(glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
}
while (!glfwWindowShouldClose(window))
{
processInput(window);
glfwSwapBuffers(window);
glfwPollEvents();
}顶点
float vertices[] = {
-0.5f, -0.5f, 0.0f,
0.5f, -0.5f, 0.0f,
0.0f, 0.5f, 0.0f
};每行表示x,y,z。注意到z为0,意味着这三个点的 相同。
需要注意的是点的坐标各个值要在[-1,1]之间
顶点缓冲对象(VBO)
可以理解为一个缓冲区,存放着许多点的位置
顶点缓冲对象是我们在OpenGL教程中第一个出现的OpenGL对象。就像OpenGL中的其它对象一样,这个缓冲有一个独一无二的ID
OpenGL有很多缓冲对象类型,顶点缓冲对象的缓冲类型是GL_ARRAY_BUFFER。OpenGL允许我们同时绑定多个缓冲,只要它们是不同的缓冲类型。
unsigned int VBO; //id
glGenBuffers(1, &VBO); //生成数量,指针地址
glBindBuffer(GL_ARRAY_BUFFER, VBO); // 绑定缓冲区类型,绑定id顶点属性、内存布局
glBufferData是一个专门用来把用户定义的数据复制到当前绑定缓冲的函数。它的第一个参数是目标缓冲的类型:顶点缓冲对象当前绑定到GL_ARRAY_BUFFER目标上。第二个参数指定传输数据的大小(以字节为单位);用一个简单的sizeof计算出顶点数据大小就行。第三个参数是我们希望发送的实际数据。
第四个参数指定了我们希望显卡如何管理给定的数据。它有三种形式:
GL_STATIC_DRAW:数据不会或几乎不会改变。GL_DYNAMIC_DRAW:数据会被改变很多。GL_STREAM_DRAW:数据每次绘制时都会改变。
// 缓冲区类型,数据大小,数据,用途
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);顶点着色器
顶点着色器用于对顶点的绘制,可以是做一个单独的程序,这就意味我们需要对它进行编程。
#version 330 core
layout (location = 0) in vec3 aPos;
void main()
{
gl_Position = vec4(aPos.x, aPos.y, aPos.z, 1.0);
}当前这个顶点着色器可能是我们能想到的最简单的顶点着色器了,因为我们对输入数据什么都没有处理就把它传到着色器的输出了
在文件中,将源码以字符串形式写入
const char *vertexShaderSource = "#version 330 core\n"
"layout (location = 0) in vec3 aPos;\n"
"void main()\n"
"{\n"
" gl_Position = vec4(aPos.x, aPos.y, aPos.z, 1.0);\n"
"}\0";编译着色器
首先创建一个着色器对象,使用id表示
unsigned int vertexShader;
vertexShader = glCreateShader(GL_VERTEX_SHADER);然后我们把顶点着色器的源码附加到这个对象上,进行编译
glShaderSource(vertexShader, 1, &vertexShaderSource, NULL);
glCompileShader(vertexShader);glShaderSource函数把要编译的着色器对象作为第一个参数。第二参数指定了传递的源码字符串数量,这里只有一个。第三个参数是顶点着色器真正的源码,第四个参数我们先设置为NULL
片段着色器
通俗理解就是对每一个像素去什么颜色进行计算的程序
#version 330 core
out vec4 FragColor;
void main()
{
FragColor = vec4(1.0f, 0.5f, 0.2f, 1.0f);
} unsigned int fragmentShader;
fragmentShader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragmentShader, 1, &fragmentShaderSource, NULL);
glCompileShader(fragmentShader);着色器程序
着色器程序对象(Shader Program Object)是多个着色器合并之后并最终链接完成的版本。如果要使用刚才编译的着色器我们必须把它们链接(Link)为一个着色器程序对象,然后在渲染对象的时候激活这个着色器程序。已激活着色器程序的着色器将在我们发送渲染调用的时候被使用
unsigned int shaderProgram;
shaderProgram = glCreateProgram();
glAttachShader(shaderProgram, vertexShader);
glAttachShader(shaderProgram, fragmentShader);
glLinkProgram(shaderProgram);激活程序
glUseProgram(shaderProgram);在glUseProgram函数调用之后,每个着色器调用和渲染调用都会使用这个程序了。
对了,在把着色器对象链接到程序对象以后,记得删除着色器对象,我们不再需要它们了:
glDeleteShader(vertexShader);
glDeleteShader(fragmentShader);链接顶点属性
顶点着色器允许我们指定任何以顶点属性为形式的输入。这使其具有很强的灵活性的同时,它还的确意味着我们必须手动指定输入数据的哪一个部分对应顶点着色器的哪一个顶点属性。所以,我们必须在渲染前指定OpenGL该如何解释顶点数据。
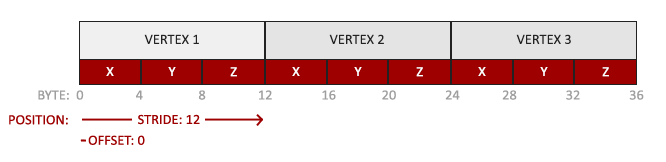
- 位置数据被储存为32位(4字节)浮点值。
- 每个位置包含3个这样的值。
- 在这3个值之间没有空隙(或其他值)。这几个值在数组中紧密排列(Tightly Packed)。
- 数据中第一个值在缓冲开始的位置。
然后我们需要告诉如何解析我们提供的点的数据
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);对于第一个函数的参数解释如下:
- 第一个参数指定我们要配置的顶点属性。还记得我们在顶点着色器中使用layout(location = 0)定义了position顶点属性的位置值(Location)吗?它可以把顶点属性的位置值设置为0。因为我们希望把数据传递到这一个顶点属性中,所以这里我们传入0。
- 第二个参数指定顶点属性的大小。顶点属性是一个vec3,它由3个值组成,所以大小是3。
- 第三个参数指定数据的类型,这里是GL_FLOAT(GLSL中vec*都是由浮点数值组成的)。
- 下个参数定义我们是否希望数据被标准化(Normalize)。如果我们设置为GL_TRUE,所有数据都会被映射到0(对于有符号型signed数据是-1)到1之间。我们把它设置为GL_FALSE。
- 第五个参数叫做步长(Stride),它告诉我们在连续的顶点属性组之间的间隔。由于下个组位置数据在3个float之后,我们把步长设置为3 * sizeof(float)。要注意的是由于我们知道这个数组是紧密排列的(在两个顶点属性之间没有空隙)我们也可以设置为0来让OpenGL决定具体步长是多少(只有当数值是紧密排列时才可用)。一旦我们有更多的顶点属性,我们就必须更小心地定义每个顶点属性之间的间隔,我们在后面会看到更多的例子(译注: 这个参数的意思简单说就是从这个属性第二次出现的地方到整个数组0位置之间有多少字节)。
- 最后一个参数的类型是void*,所以需要我们进行这个奇怪的强制类型转换。它表示位置数据在缓冲中起始位置的偏移量(Offset)。由于位置数据在数组的开头,所以这里是0。我们会在后面详细解释这个参数。
顶点数组对象
顶点数组对象(Vertex Array Object, VAO)可以像顶点缓冲对象那样被绑定,任何随后的顶点属性调用都会储存在这个VAO中。这样的好处就是,当配置顶点属性指针时,你只需要将那些调用执行一次,之后再绘制物体的时候只需要绑定相应的VAO就行了。这使在不同顶点数据和属性配置之间切换变得非常简单,只需要绑定不同的VAO就行了。刚刚设置的所有状态都将存储在VAO中
OpenGL的核心模式要求我们使用VAO,所以它知道该如何处理我们的顶点输入。如果我们绑定VAO失败,OpenGL会拒绝绘制任何东西。
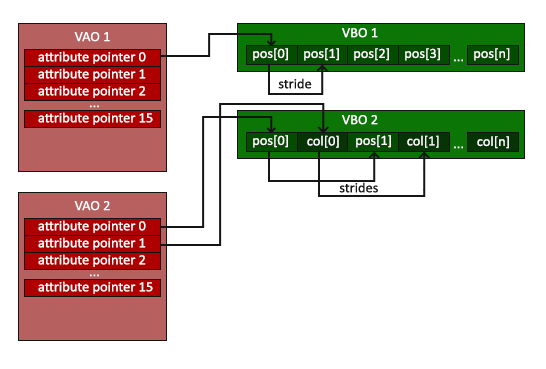
unsigned int VAO;
glGenVertexArrays(1, &VAO);
//绑定
glBindVertexArray(VAO);
元素缓冲对象
在渲染顶点这一话题上我们还有最后一个需要讨论的东西——元素缓冲对象(Element Buffer Object,EBO),也叫索引缓冲对象(Index Buffer Object,IBO)。要解释元素缓冲对象的工作方式最好还是举个例子:假设我们不再绘制一个三角形而是绘制一个矩形。我们可以绘制两个三角形来组成一个矩形(OpenGL主要处理三角形)。这会生成下面的顶点的集合:
float vertices[] = {
// 第一个三角形
0.5f, 0.5f, 0.0f, // 右上角
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, 0.5f, 0.0f, // 左上角
// 第二个三角形
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, -0.5f, 0.0f, // 左下角
-0.5f, 0.5f, 0.0f // 左上角
};可以看到,有几个顶点叠加了。我们指定了右下角和左上角两次!一个矩形只有4个而不是6个顶点,这样就产生50%的额外开销。当我们有包括上千个三角形的模型之后这个问题会更糟糕,这会产生一大堆浪费。更好的解决方案是只储存不同的顶点,并设定绘制这些顶点的顺序。这样子我们只要储存4个顶点就能绘制矩形了,之后只要指定绘制的顺序就行了。如果OpenGL提供这个功能就好了,对吧?
值得庆幸的是,元素缓冲区对象的工作方式正是如此。 EBO是一个缓冲区,就像一个顶点缓冲区对象一样,它存储 OpenGL 用来决定要绘制哪些顶点的索引。这种所谓的索引绘制(Indexed Drawing)正是我们问题的解决方案。首先,我们先要定义(不重复的)顶点,和绘制出矩形所需的索引:
float vertices[] = {
0.5f, 0.5f, 0.0f, // 右上角
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, -0.5f, 0.0f, // 左下角
-0.5f, 0.5f, 0.0f // 左上角
};
unsigned int indices[] = {
// 注意索引从0开始!
// 此例的索引(0,1,2,3)就是顶点数组vertices的下标,
// 这样可以由下标代表顶点组合成矩形
0, 1, 3, // 第一个三角形
1, 2, 3 // 第二个三角形
};
unsigned int EBO;
glGenBuffers(1, &EBO);
//绑定
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);